Scality - One Ring to Rule Them All?
- 3 minsThis post was previously hosted on a different site and then migrated here.

Last week I was fortunate enough to have been invited by Stephen Foskett to attend Storage Field Day 11 in San Jose.
If you’re unaware of what the Tech Field Day events are, you should take a look at the website. They run excellent events that give a real insight into IT vendors and their technologies.

One of the vendors that I was most looking forward to seeing present was Scality, who have a very interesting software defined object storage play.
So what are Scality doing, and why the Lord of the Rings reference?
Fundamentally Scality’s main product is called the Scality RING, and what nerd can avoid making a Tolkien reference when people start talking about rings?
The RING is fully software defined object storage optimised for cloud native architectures and applications. It runs on any commodity x86 hardware, is based upon standard Linux packages, and scales linearly for both performance and capacity. I asked the question “how big can it scale?” and I was told that there’s no limit.
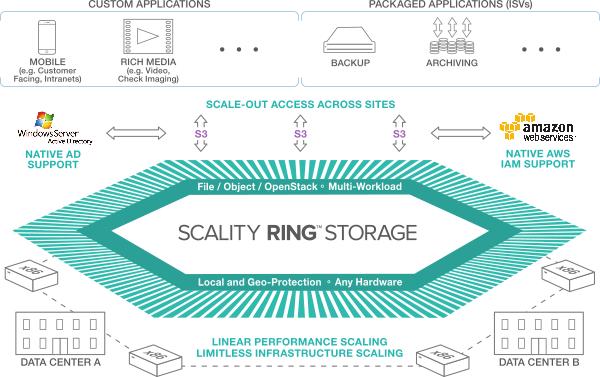
Scality formed out of an email software company where they were asked to help Service Providers compete with the Gmail and Hotmails of this world. As CTO Giorgio Regni said, “Buying a huge enterprise SAN to store pictures of cats does not make a lot of sense..”. Scality was born out of the need for a more scalable, object based solution, and they signed up their first customer (a large SP, unsurprisingly) pretty much immediately after launching in 2009.
From a technology point of view Scality natively supports NFSv3, SMB2.0, and FUSE for file access to their scale out file system, OpenStack APIs, the ubiquitous and obligatory S3 and CDMI object APIs, and features both local and geo-distributed data protection via replication and erasure coding.
Recently v.6 of the RING software was released:
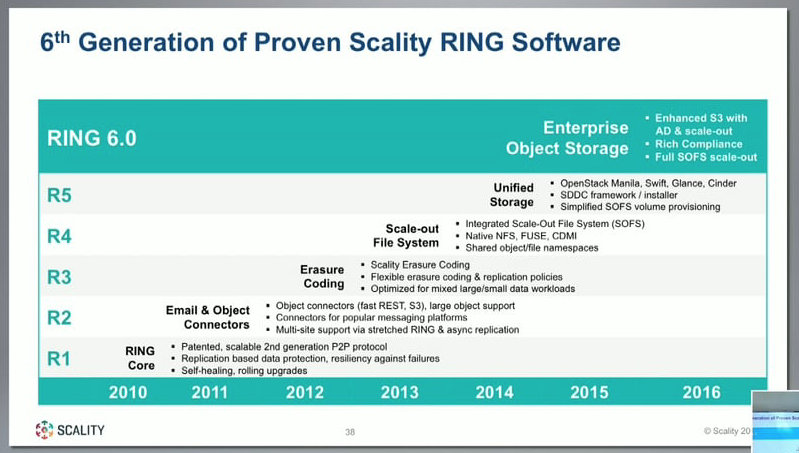
This release predominently focussed on features requested by the Enterprise, including -
- Full AD and AWS IAM integration
- WORM and encryption features (with reference cases of migration from EMC Centera and NetApp Snaplock).
- Integrated load-balancing and connector failover for SOFS.
- Quotas & reporting (can be extracted via CLI/API in addition to the GUI).
- Versioning/Undelete functionality.
- New statistics repositiory for reporting (Eleastic Search based, real-time data collection, API driven) - integrations into Graphana, Elastic Search for statistics, and Swagger for API documentation.
In addition, one of the more interesting releases was the Scality S3 Server. This is a free tool that runs in a Docker container which allows developers to test their applications against S3 based object storage on their own workstations without impacting the production RING.
Brilliantly the development of this tool came out of a Hackathon that Scality ran from their Paris office, and 8 people were employed off the back of that. That’s a nice way to recruit people and grow the community around a product, if you ask me.
I think Scality have one of the more complete object storage solutions on the market right now, and the fact it’s completely decoupled from any hardware makes it incredibly versatile depending on your usecase. I’m very much looking forward to seeing more of them going forwards.
If you want to know more about object storage in general, Enrico Signoretti has written several good pieces, and one of my Storage Field Day peers James Green has written about Object Storage here.
The full Scality presentations from Storage Field Day can also be found here.
Disclaimer: This blog is part of my series on Storage Field Day 11. I was personally invited to attend Storage Field Day 11 as an independent delegate, with GestaltIT covering my travel, accommodation, and the majority of my subsidence costs. However I was not compensated for my time. I am not required to blog on any content and blog posts are not edited or reviewed by the presenters or the respective companies prior to publication.

Ed Morgan
GTM Technical Lead @ Rubrik, I like the Cloud, automation, and picking heavy things up then putting them down again.